いきなり、どこかのクイズバラエティ番組みたいな問題を出してしまいましたが…皆さん、わかりますか?当てずっぽうで選ぶのではなく、ちゃんと理由も説明してください。
様々な知識の中から法則を見つけ出すことができれば、答えは導き出せるはずなのですが、結構難易度が高いかも知れません。しかし、たぶん小学生でもわかる子はいるはずです。
もちろん、唐突にこんな問題をやりたくなったわけではありません。きっかけは、この数列が合理的な意味を持つ、ある世界の話です。
我が家の新しいクルマ・ステップワゴン e:HEV スパーダ「ブラックパール2世号」には、純正ディーラーオプションのGathers(ぎゃざず)ナビ・VXM-217VFNiが載せてあります。今どきのカーナビは、地図上に現在位置を表示したりルートを探索、案内したりするだけでなく、オーディオ機能も提供するのが大事な役割で、この製品も例に漏れず、相当多彩なAVソースを鳴らせます。

そのなかでいちばん出番が多いのが、SDメモリーカードの中に保存した音楽データ。MP3、WMA、FLACなどが再生できるようになっています。CDからリッピングしてパソコンの中に貯め込んであるものから、クルマで聴きたいものを選んでSDメモリーカードに転送しています。とはいえ、ライブラリーのほとんどを転送しても、128GBのSDXCはまだ余裕たっぷりなのですが。
基本的には、アーティスト別、アルバム別にフォルダー階層が構築されているので、この順番で再生することになりますが、CategorySearch(カテゴリーサーチ)という機能があって、フォルダーとは無関係にそれぞれの項目をキーにして順番に再生することができます。特に、「♪TRACK」を選ぶと、すべての曲がフラットに並び、曲名順に再生されます。明らかに規則性を持って並べられているはずなのに、ある意味ランダムで何が出てくるかわからない…と言う面白さがあります。
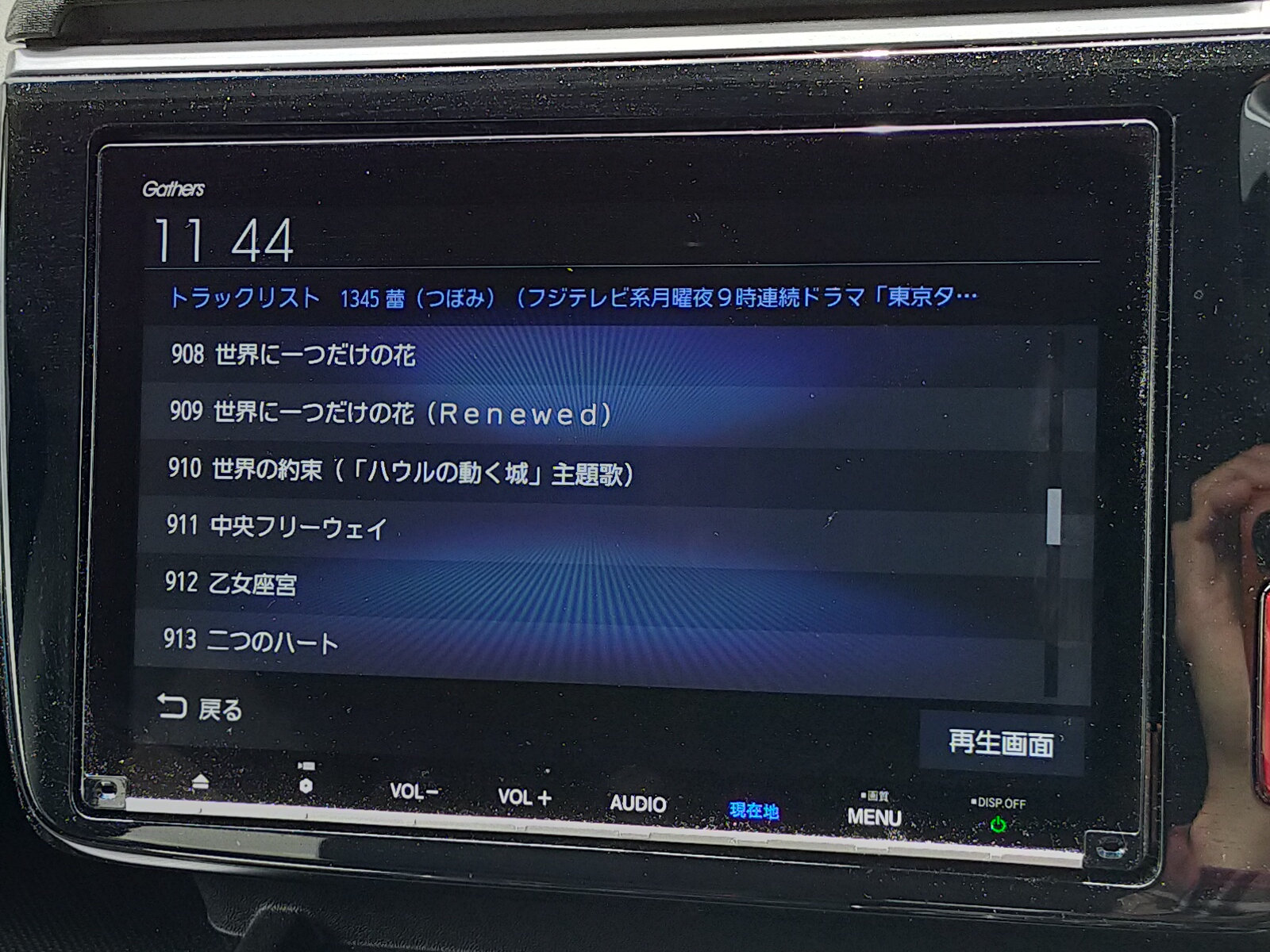
しかし、この「曲名順」というのが結構曲者。数字やアルファベット、ひらがなやカタカナについては、直感的にわかりやすい順番になっているのですが、漢字の並び順がどうなっているのか、最初は全くわからずに戸惑いました。読み仮名が入っているわけではないので、読みの五十音順ではないのは確かなのですが…。
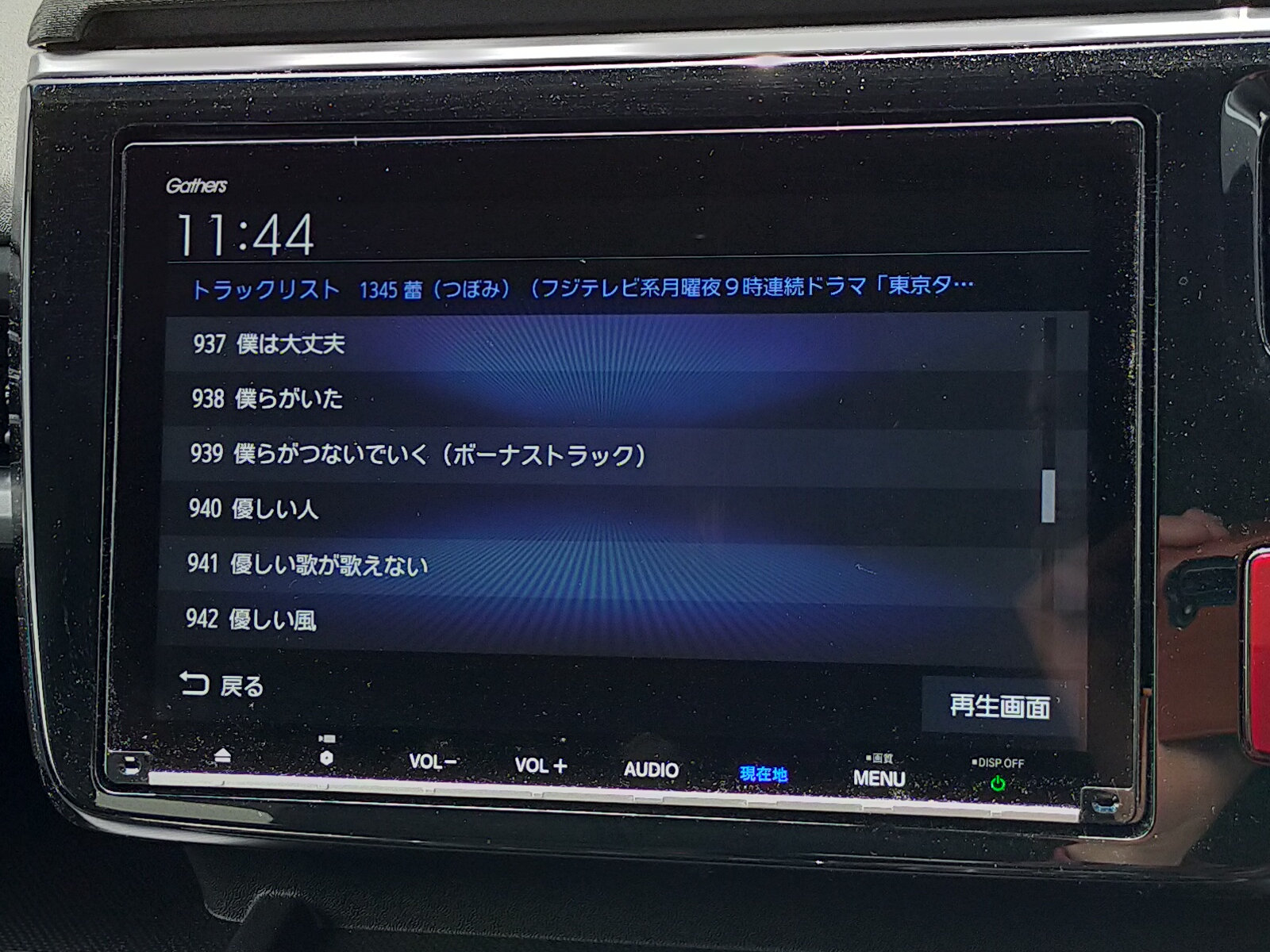
一見脈絡がないように見えるのですが、並んでいるのを見ていると傾向が見えてきます。基本的には画数の少ない字から画数の多い字へ…というひとかたまりのグループが、いくつか並んでいます。そして、例えば「にんべん」のような同じ部首の漢字が並んでいるのもわかります。総合すると、「部首の画数順、各部首内では画数順」ということで良さそうです。
何故そうなるのか?なのですが、これは、カーナビに限らず情報機器の中で漢字がどのように処理されているのかに関わってきます。現在、漢字をデジタルデータとして表現する際に使われているのは、世界中のすべての文字を同じ一覧表に並べた「Unicode(ゆにこーど)」と呼ばれる文字コード体系が主流です。漢字については、同じような形の字については別の国で使っているものでも同じコードに割り付けよう!ということで、「CJK統合漢字」という形で定められています。China、Japan、Koreaの頭文字を取ってCJK、ですね。
CJK統合漢字では、文字コードの割り付け順は「部首順の画数順」ということで決められています。「曲名順」は文字コード順に並ぶため、漢字交じりの曲名はこんな順番になる…ということのようです。
ここで今回のタイトルの問題の解答をしておこうかと思います。ここに並べられていた数字を漢数字に書き換えると「一、七、三、九、二」となり、これは「部首順の画数順」になっています。ちなみに、一から九までの9文字を文字コード順に並べるとこんな風になります。↓
| 順序 | 漢数字 | 部首 | 部首画数 | 画数 | Unicode |
|---|---|---|---|---|---|
| 1 | 一 | 一(いち) | 1 | 1 | 4E00 |
| 2 | 七 | 一 | 1 | 2 | 4E03 |
| 3 | 三 | 一 | 1 | 3 | 4E09 |
| 4 | 九 | 乙(おつ) | 1 | 2 | 4E5D |
| 5 | 二 | 二(に) | 2 | 2 | 4E8C |
| 6 | 五 | 二 | 2 | 4 | 4E94 |
| 7 | 八 | 八(はち) | 2 | 2 | 516B |
| 8 | 六 | 八 | 2 | 4 | 516D |
| 9 | 四 | 囗(くにがまえ) | 3 | 5 | 56DB |
…というわけで、正解は「5」になります。「Unicodeの並び順なんてわかるわけないじゃないか」と言われそうですが、「部首順の画数順」という並び方は、多くの方に馴染みがあるはずです。これは、漢和辞典で漢字が並べられている順番と同じ。ですから、IT系の知識には全く縁がなくても、漢和辞典が出てくれば理由の説明は正解!と言って良いでしょう。実は、部首をどう扱うかも、ツッコミ始めるとかなり深い沼にハマりかねないのですが…。
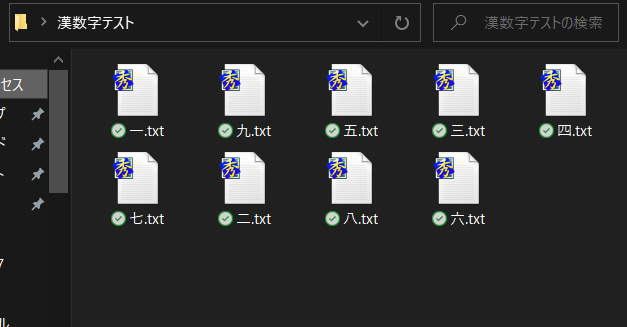
ところで、私たちには非常に身近な情報処理機器であるWindowsパソコンだと、これとはまた異なる挙動を示します。例えば、エクスプローラー上で漢数字の名称を付けたファイルを名前順に並べ替えてみるとこんな感じ。一、九、五、三、四、七、二、八、六となります。先ほどの順番とは明らかに違いますよね。
これは、Windows内部で使われている「シフトJIS」という文字コード体系で並べ替えられているから。「JIS」の名前が付くとおり、Unicodeよりも前から日本国内の共通規格として使われているものです。シフトJISでは、漢字は代表的な読み(基本的には音読み)の五十音順に並べられています。いち、く、ご、さん、し、しち、に、はち、ろく…となるわけですね。
UnicodeとシフトJISのどちらでも、漢数字を文字コード順に並び替えると、数の大きさの順には並ばない…という現象が起きることになります。とはいえ、こうした違和感が起きるのは漢数字だけですし、いずれにしてもそのままでは本来の読みの順には並ばないわけですから、気にしても仕方ないかも。「文字コード順」に期待するのが筋違いです。
読みは文字から推測できるのでしょうけれど、厳密には読み仮名を別のデータとして持つしかありません。考えてみると、同じ文字の読み方ばかりか意味までもが(漢字は本来表意文字のはずなのに)文脈によって変化していく一方で、同じ発音のことばにも数多くの意味がある日本語というのは、コンピューターに処理させようとすると実に面倒な言語です。そこをフィールドにして研究・開発に取り組んでいる皆さんには敬意を表します。
コメントを残す